

DeepSeek-R1 14B Running Locally On Linux - Technology Overview
https://video.fosshq.org/videos/watch/270f0453-8340-4623-b1f6-b0d8c97b5413

DeepSeek-R1 14B Running Locally On Linux - Technology Overview
https://video.fosshq.org/videos/watch/270f0453-8340-4623-b1f6-b0d8c97b5413
Came across this great blog entry about how to set up a RAG with Ollama and Open WebUI
#AI #RAG #Ollama #OpenWebUI

Found a great local #AI app for anyone who wants a simple and easy way to have their own private offline AI at their fingertips. #Ollama https://kleedesktop.com

Harnessing AI in C# with Microsoft-Extensions-AI, Ollama, and MCP Server | by Laurent Kempé.
laurentkempe.com/2025/03/15/h...
#ai #csharp #dotnet #ollama
Laurent Kempé - Harnessing AI ...
Harnessing AI in C# with Microsoft-Extensions-AI, Ollama, and MCP Server | by Laurent Kempé.
Finally, the setting I've been looking for is disabled and I can move on with life. Oh don't worry, it's not in the usual place of course, every device must be special, if that wasn't ensured by the proclivity in Linux towards "yes there are breaking changes which we might not have documented. submit a bug if you find one, we can't be expected to document releases effectively. what, did you expect that is this a BSD phone? lol,no it's android."
Pausing to remind myself that since this is the modern era, finding the answer amongst the vastness of potential data sources and search engine results... the answer was rapidified by asking my local LLM about specific Android version options which are part of the manufacturer's modified UX element tree:
> "On a 'TCL NXTPAPER 40 5G' phone, running TCL-UI version 5.0.YGC0, included in the custom settings for "simulated e-ink paper', related to Accessibility Features, where is the floating button for screen color inversion?"
and there you have it, one query. I should have defaulted to that by default.
also, Gemma3 is very fast on Ollama... now I need to test the quantized version "Fallen-Gemma3-4B-v1g-Q6_K" for a comparison.
Умная погода становится ещё умнее
Оказывается, апишка от open weather возвращает температуру в кельвинах. Поэтому пришлось обрабатывать входящий json, чтобы перевести всё в метрическую систему, чтобы в ответе от модели было меньше мусора
А ещё добавил в контекст текущее время и приложение больше не предлагает мне надеть очки и панаму в два часа ночи xD #ai #ai_agents #ollama #python

 [Hands-ON] Discover how Retrieval-Augmented Generation combines real-time data retrieval with #AI to deliver accurate, context-aware answers. Learn how this cutting-edge technology is transforming how we interact with intelligent systems.
[Hands-ON] Discover how Retrieval-Augmented Generation combines real-time data retrieval with #AI to deliver accurate, context-aware answers. Learn how this cutting-edge technology is transforming how we interact with intelligent systems.
Pre-requisites: Laptop with #Docker, #Python and #Ollama installed. Register Now: https://lu.ma/x045dbot

Smart weather in your terminal! #AI #ollama #python #pydantic_ai #ai_agents
 tool displaying the weather for Phnom Penh, Cambodia. It includes the current weather conditions (temperature, humidity, wind speed, and visibility), clothing recommendations, suggested activities, and a cautionary note about high humidity and heat-related risks. The text is formatted with headings and bullet points, with warnings highlighted in red for emphasis.")
Testing Open WebUi with Gemma:3 on my proxmox mini PC in a LXC. My hardware is limited, 12th Gen Intel Core i5-12450H so I’m only using the 1b (28 token/s) and 4b (11 token/s) version for now.
Image description is functioning, but it is slow; it takes 30 seconds to generate this text with the 4b version and 16G allocated for the LXC.
Next step, trying this on my Mac M1.

So, following a blog post[1] from @webology and some guides about #VSCode plugins online, I set up #ollama with a number of models and connected that to the Continue plugin.
My goal: see if local-laptop #llm code assistants are viable.
My results: staggeringly underwhelming, mostly in terms of speed. I tried gemma3, qwen2.5, and deepseek-r1; none of them performed fast enough to be a true help for coding.
[1] https://micro.webology.dev/2024/07/24/ollama-llama-red-pajama/
So, I did it. I hooked up the #HomeAssistant Voice to my #Ollama instance. As @ianjs suggested, it's much better at recognizing the intent of my requests. As @chris_hayes suggested, I'm using the new #Gemma3 model. It now knows "How's the weather" and "What's the weather" are the same thing, and I get an answer for both. Responses are a little slower than without the LLM, but honestly it's pretty negligible. It's a very little bit slower again if I use local #Piper vs HA's cloud service.
Testing out the newly released #Gemma3 model locally on #ollama. This is one of the more frustration aspects of these LLMs. It must be said that LLMs are fine for what they are, and what they are is a glorified autocomplete. They have their uses (just like autocomplete does), but if you try to use them outside of their strengths your results are going to be less than reliable.

It is really worth buying any of these Nvidia Jetson boxes? By watching videos running #ollama in there looks like it’s way slower than my macbookpro
The sun has returned!
I mean, it has always been there. Relatively speaking in the same place it was over the last few months. But the Earth’s tilt is such that as it revolves around the nearest star the portion on which I live (the northern hemisphere) is getting ever so slightly closer and faces it just long enough that temperatures are beginning to warm.
And I’m a very happy person […]


Нейросетевой переводчик в командной строке, или Приручаем API Ollama и OpenWebUI
Связку из Ollama и OpenWebUI я использую больше года, и она является моим рабочим инструментом в части работы с документацией и контентом и по-настоящему ускорила работу по локализации документации HOSTKEY на другие языки. Но жажда исследований не отпускает, и с появлением относительно вменяемой документации к API у OpenWebUI возникло желание написать что-то, автоматизирующее работу. Например, перевод документации из командной строки.

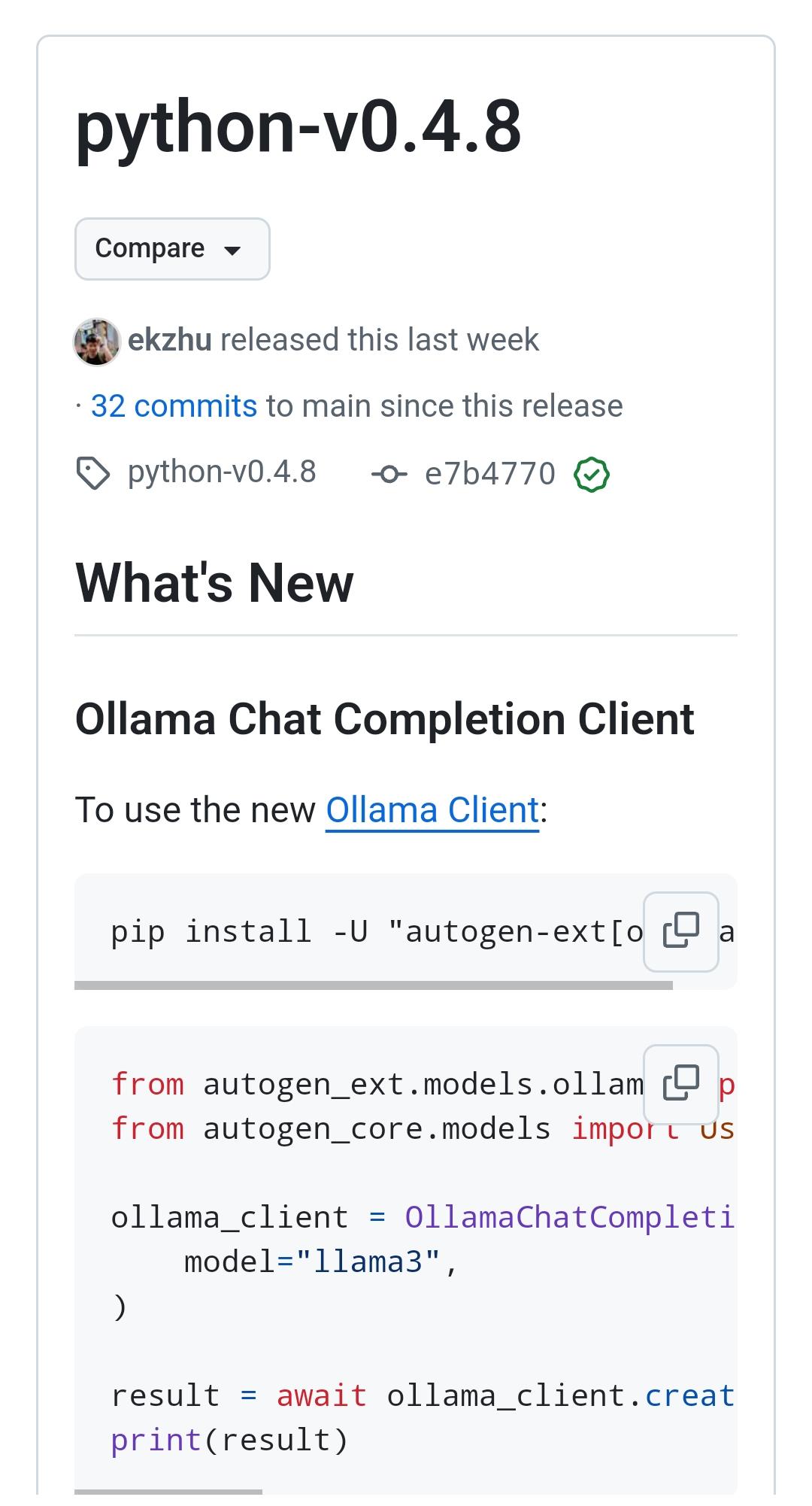
 La versione 0.4.8 di #Autogen introduce una novità molto interessante: il supporto nativo ai modelli di #Ollama.
La versione 0.4.8 di #Autogen introduce una novità molto interessante: il supporto nativo ai modelli di #Ollama.
 Questo apre la via allo sviluppo di applicazioni multi-agent sfruttando #LLM che funzionano in locale
Questo apre la via allo sviluppo di applicazioni multi-agent sfruttando #LLM che funzionano in locale
 Considerando le performance dei recenti modelli open-source, questi sistemi diventano davvero potenziali soluzioni.
Considerando le performance dei recenti modelli open-source, questi sistemi diventano davvero potenziali soluzioni.
___
 𝗦𝗲 𝘃𝘂𝗼𝗶 𝗿𝗶𝗺𝗮𝗻𝗲𝗿𝗲 𝗮𝗴𝗴𝗶𝗼𝗿𝗻𝗮𝘁𝗼/𝗮 𝘀𝘂 𝗾𝘂𝗲𝘀𝘁𝗲 𝘁𝗲𝗺𝗮𝘁𝗶𝗰𝗵𝗲, 𝗶𝘀𝗰𝗿𝗶𝘃𝗶𝘁𝗶 𝗮𝗹𝗹𝗮 𝗺𝗶𝗮 𝗻𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: https://bit.ly/newsletter-alessiopomaro
𝗦𝗲 𝘃𝘂𝗼𝗶 𝗿𝗶𝗺𝗮𝗻𝗲𝗿𝗲 𝗮𝗴𝗴𝗶𝗼𝗿𝗻𝗮𝘁𝗼/𝗮 𝘀𝘂 𝗾𝘂𝗲𝘀𝘁𝗲 𝘁𝗲𝗺𝗮𝘁𝗶𝗰𝗵𝗲, 𝗶𝘀𝗰𝗿𝗶𝘃𝗶𝘁𝗶 𝗮𝗹𝗹𝗮 𝗺𝗶𝗮 𝗻𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: https://bit.ly/newsletter-alessiopomaro














 ~eva~
~eva~














